tldr; In diesem Beitrag möchte ich euch einen Einblick geben, wie man kleinere Chatbots mit Ollama auf dem eigenen Rechner laufen lassen und für die eigene Arbeit einbinden kann...
Künstliche „Intelligenz“ ist inzwischen in vielen Bereichen des digitalen Lebens angekommen und jederzeit in Form von Chatbots im Web und auf dem Smartphone in Reichweite. Auch wenn ihr nicht aus dem IT-Bereich kommt oder euch weniger für die Technik (und Mathematik) dahinter interessiert, gibt es eine Vielzahl an einschlägigen Themen, mit denen man sich beschäftigen kann. Dazu gehören praktische Techniken (wie effizientes Prompting für bessere Antworten) oder ein tieferes Verständnis für die „Denkweise“, also Stärken und auch Grenzen solcher Sprachmodelle. Wichtige Fähigkeiten für den zukunftssicheren Umgang mit KI!
KI im Hosentaschenformat
Die generativen Sprachmodelle (LLMs) der großen Anbieter wie OpenAI, Google und Anthropic sind sehr speicherhungrig und benötigen jede Menge Rechenpower. Davon abgesehen gibt es auch kleinere Modelle, welche auf die Leistung von privaten PCs zugeschnitten und teilweise auch quelloffen verfügbar sind. Ist euer Rechner einigermaßen aktuell, könnt ihr auch solche Sprachmodelle selbst ausführen, die auch – je nach Anwendungsfall – ganz ordentliche Ergebnisse liefern. Sie bieten sich gerade zu an, sich auszuprobieren und die Technik besser kennenlernen zu können.
Was ist eigentlich ein „Modell“? Dabei handelt es sich sozusagen um einen Speicherpunkt des komplexen Systems, welches darauf trainiert wurde, die jeweils beste Antwort auf eure Eingabe vorherzusagen. Viele dieser frei verfügbaren Modelle können in Form von Dateien heruntergeladen werden.
Das sind die Vorteile
Warum sollte ich das machen, wenn es doch mit ChatGPT, Gemini und co. kostenlose Chatbots im Netz gibt? Hier sind einige Argumente:
- Privatsphäre: Da die KI auf eurem eigenen Rechner läuft, bleiben auch eure Daten dort. Eure (sensiblen) Chatverläufe werden nicht an die Anbieter geschickt und möglicherweise im Rahmen des weiteren KI-Trainings wiederverwendet oder für zugeschnittene Werbung analysiert.
- Lernen: Wie bereits oben erwähnt, eignen sich solche Modelle gut, um praktische Erfahrungen mit der Technik zu sammeln. Gerade die kleineren Modelle stoßen auch schnell an ihre Grenzen und machen Fehler, was spannend zu beobachten sein kann.
- Kostenlos und herunterladbar: Lokale Modelle, einmal heruntergeladen, funktionieren auch ohne Internetanbindung. Mit entsprechenden Kenntnissen könnt diese Modelle mit eigenen Daten oder spezifischen Inhalten trainieren (z. B. eure Dokumente, Fachbegriffe oder persönliche Vorlieben), um sie für eure individuellen Bedürfnisse anzupassen.
Modell-Registries und Programme für den lokalen Einsatz
Um ein Sprachmodell auf dem eigenen Rechner starten zu können, benötigt ihr grundsätzlich drei Dinge:
- Eine entsprechende Ausführungsumgebung für die Sprachmodelle (einen Hintergrunddienst),
- eine Benutzeroberfläche für die bequeme Interaktion sowie
- eine Download-Quelle für die Modelldateien (sog. Registry).
Diese können durch ein oder mehrere Programme bereitgestellt werden. Bekannte Desktop-Anwendungen sind llama.cpp, Ollama und LMStudio, die jeweils für Windows, Mac und GNU/Linux verfügbar sind. Zwischen den Anwendungen gibt es Unterschiede bei Funktionsumfang und Zielgruppe – ich fokussiere mich in diesem Beitrag auf Ollama, weil es alle drei oben genannten Punkte in einer Installation bereitstellt und einfach zu bedienen ist.
Ein möglicher Bezugspunkt für die Modelldaten ist die bekannte Plattform huggingface für maschinelles Lernen. Ob ihr ein Sprachmodell in der jeweiligen Anwendung nutzen könnt, hängt davon ab, in welchem Dateiformat es bereitgestellt wird. Bei huggingface gibt es eine entsprechende Filteroption dafür. Bei Ollama könnt ihr auch direkt die interne Registry verwenden, was ich in diesem Beitrag machen werde. Hinweis: Ladet Modelle nur aus der offiziellen Ollama Registry oder anderen vertrauenswürdigen Quellen herunter.
Hardware-Voraussetzungen
Für Ollama braucht ihr keinen Super-Rechner. Ein halbwegs aktueller Laptop oder PC mit mind. 16 GB RAM Arbeitsspeicher sollte hierfür ausreichen, 32 GB sind aber noch besser.
Eine eigenständige, leistungsfähige Grafikkarte beschleunigt die Ausgabe des generierten Textes zwar erheblich, ist aber keine Pflicht. Letztendlich hängt das vor allem davon ab, ob das von euch ausgewählte Sprachmodell bei der Ausführung (vollständig) in den Arbeitsspeicher passt. Habt ihr einen Grafikchip mit KI-Beschleunigung (z.B. eine neuere Grafikkarte von NVIDIA), wird das Modell stattdessen in den Videospeicher geladen.
Als Daumenregel: Mit 16 GB Arbeitsspeicher könnt ihr Modelle bis ca. 7B Größe verwenden, bei 32 GB RAM sind es je nach Grafikkarte aus eigener Erfahrung 12 -32B Größe. Eine Liste der unterstützten Geräte findet ihr hier.
Ollama installieren
Ollama bietet eine Laufzeitumgebung für Sprachmodelle sowie eine minimale, einfache Benutzeroberfläche für Chats. Neue Modelle können direkt in der Anwendung heruntergeladen werden. Die Installation erfolgt über einen normalen Windows Installer, oder auch über Tools wie winget (zum Download gehts hier). Für den Download und die Nutzung der freien Modelle ist übrigens kein Ollama-Konto notwendig (bei der Installation einfach überspringen).
Grundsätzlich gibt es zwei Möglichkeiten, Ollama zu nutzen und neue Sprachmodelle herunterzuladen. Über die Desktop App, oder mit dem ollama Befehl über die Kommandozeile (unter Windows 11: Das vorinstallierte PowerShell Terminal). Der ollama Dienst funktioniert im Prinzip wie die Container-Verwaltung Docker und läuft im Hintergrund (Tray Icon unten in der Symbolleiste). Ich möchte euch in diesem Beitrag zunächst zweiteres zeigen, weil ich es übersichtlicher und lehrreicher finde.
Beispiel: Mit ollama list seht ihr alle derzeit auf dem PC heruntergeladenen Modelldateien. Weitere Befehle entdeckt ihr mit ollama --help.

ollama list einen Überblick über heruntergeladene Sprachmodelle bekommen. Weitere Befehle findet ihr über ollama --help Download neuer Modelle und Empfehlungen
Über die Ollama Registry könnt ihr nach Modellen suchen. Grundsätzlich ist die Auswahl nicht ganz leicht, so gibt es bei der Modellauswahl mehrere Dinge zu beachten: Zum einen die Sprache(n), mit denen ein Modell trainiert wurde und danach auch „spricht“. Zum anderen gibt es Allzweck-Modelle (general purpose), welche gut für Chats geeignet sind und spezialisierte Modelle, welche für bestimmte Aufgaben wie Programmierung oder kreatives Schreiben zugeschnitten sind. Und dann gibt es noch den persönlichen Geschmack (wie Stil oder Charakter des erzeugten Textes). Die Anzahl der Modellparameter bestimmen unmittelbar die Leistungsfähigkeit und gleichzeitig den Speicherbedarf (billion (engl.) = Milliarden). Es gibt „destillierte“ Modelle, bei denen es sich soz. um kleine, weniger präzise Schwestern der großen Sprachmodelle handelt, die sonst nicht in den Speicher eines Desktop-PCs passen würden.
Herunterladen könnt ihr das jeweilige Modell mit dem Befehl ollama pull und dem vollen Modellnahmen:Version, wie beispielsweise ollama pull mistral-nemo:12b .
Zum Ausprobieren empfehle ich euch llama3.1:8b [1], etwas besser gefällt mir persönlich mistral-nemo:12b [2]. Beide Modelle sind zwar schon etwas älter (2024), aber für universelle Aufgaben geeignet und unterstützen auch mehrere Sprachen. Die Modelle mistral-small3.2:24b [3], gpt-oss:20b [4] (quelloffene Variante von ChatGPT) sind etwas neuer und nochmal einen Tick leistungsfähiger, benötigt allerdings mehr Speicher. Für kreatives Schreiben in verschiedenen Sprachen bietet sich auch aya-expanse:32b [5] an.
Chat starten
Um mit einem Modell zu „sprechen“, ruft ihr es einfach mit dem vollen Namen auf im Terminal auf: ollama run <Modellname>. Danach landet ihr in einem interaktiven Dialog, den ihr wie gewohnt nach belieben fortführen könnt.

Etwas bequemer und mit Session-Historie geht es auch über die einfache Ollama Desktop-App, die in den neueren Versionen von Ollama mitinstalliert wird (über das Startmenü zu finden). Ich empfehle euch trotzdem, hollama auszuprobieren (siehe unten).
Tweaks für Ollama
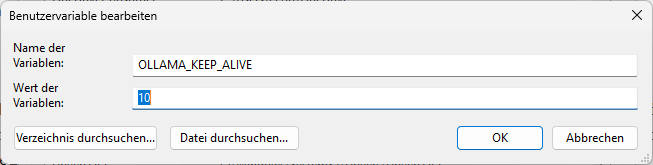
Damit Ollama den Text generieren kann, muss das Modell zunächst vollständig in den (Video-)Speicher geladen werden. Das kostet beim ersten Mal etwas Zeit, danach geht die Antwort aber flott. Das Modell wird dann für weitere 5 Minuten im Speicher gehalten, bevor dieser wieder freigegeben wird. Arbeitet ihr gerade an einer Sache, wo ihr sporadisch das Gespräch fortführen wollt, kann das hinderlich sein. Durch das Setzen der Benutzer-Umgebungsvariable OLLAMA_KEEP_ALIVE könnt ihr diese Zeit selbst festlegen („Umgebungsvariable“ im Startmenü eingeben).
Als Modell-Kontext wird der vorhergehende Teil eines Chatverlaufs, Dokumentinhaltes etc. (Tokens) bezeichnet, auf den das Modell beim generieren der aktuellen Antwort berücksichtigen kann. Je größer dieser ist, desto mehr kann sich das Modell „merken“, andererseits steigt auch hier der Speicherbedarf stark an und die Antwort wird langsamer. Die maximale Kontextgröße ist durch die Modellkapazität beschränkt (ihr findet diese Info auf der jew. Registry-Seite). Ollama passt die erlaubte Kontextgröße je nach eurem verfügbaren (Video-)Speicher bereits automatisch an. Ihr könnt das aber auch selbst nach eurem Geschmack ändern, entweder über die Ollama Desktop App oder über eine Umgebungsvariable. Mehr Details siehe hier.
Hollama
Hollama ist eine Desktop (Web) App, die zum Chatten mit Ollama verwendet werden kann (Download EXE 0.35.1 hier). Ich empfehle euch, Sie mal auszuprobieren. Sie hat viele Gemeinsamkeiten mit der offiziellen Ollama Desktop App, aber zwei entscheidende Vorteile. Zum einen könnt ihr darüber per Modell bequem spezifische Einstellungen vornehmen welche das Antwortverhalten eines Modells verändern, wie beispielsweise die oft erwähnte Temperatur (diese steuert, wie kreativ oder vorhersehbar die Antworten des Modells sind).
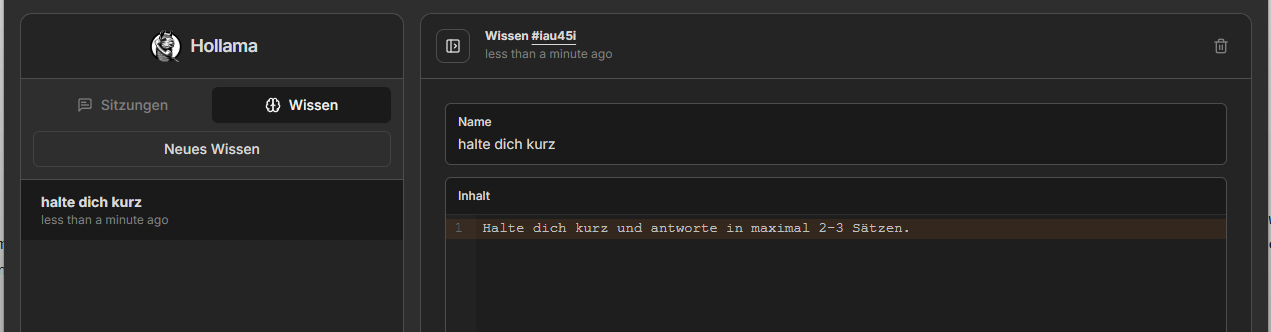
Zum anderen bietet Hollama an, „Wissen“ zu erstellen: Das sind im Prinzip einfach Textbausteine, die ihr euch selbst zusammenschreiben sollt, wie zum Beispiel die Rolle des Modells, das gewünschte Antwortformat, bestimmte Regeln etc. Bei einem neuen Chat könnt ihr euch dieses Wissen einfach zusammenklicken und euch beim Chat auf die eigentliche Sache fokussieren.
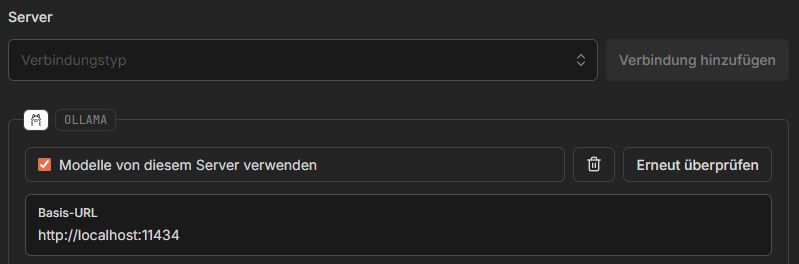
Nach der Installation müsst ihr in den App-Einstellungen zunächst prüfen, ob Ollama als „Server“ korrekt hinterlegt ist. Ihr findet die Auswahl im Dropdown-Menü für die Verbindung. Falls nicht automatisch eingetragen, wählt die folgende Standard-Adresse: http://localhost:11434 . Der Ollama Dienst muss dafür gestartet sein und im Hintergrund laufen.
Weiterführende Links
- Vorteil von Open Source LLMs und weitere Modellempfehlungen | Frauenhofer IESE
- Modellempfehlungen mit Anwendungsschwerpunkten | DataCamp
- ChatGPT, Gemini, Claude & Co erklärt: Wie Maschinen Sprache verstehen | Terra X Lesch & Co (auf Youtube)
- Anonymisierten Zugriff auf viele kommerzielle Modelle ohne Anmeldung | Duck.ai von DuckDuckGo
Einige Anwendungsbeispiele
Ihr fandet das hilfreich? In einem folgenden Beitrag schaue ich mir verschiedene Beispiele an, wofür man solche lokalen Sprachmodelle nutzen kann. Abonniert gerne meinen Blog, um auf dem Laufenden zu bleiben.. 🙂


Hinterlasse einen Kommentar